嗨嗨大家好!今天我們終於要進入 SRE 方法論的最後一條:效率與性能,這裡是今天讀的原文出處:Introduction,那我們開始囉!
書中提到:
一個服務的利用率指標通常依賴於這個服務的工作方式以及對容量的配置與部署上。如果能夠通過密切關注一個服務的容量配置策略,進而改進其資源利用率,這可以非常有效地降低系統的總成本。
GCP 上也根據各個資源設定了資源利用率的指標,下面舉一個 K8s 的例子:
Avg CPU Usage / Request
Metric:
kubernetes.io/container/cpu/core_usage_time
kubernetes.io/container/cpu/request_cores
Description:
kubernetes.io/container/cpu/core_usage_time
kubernetes.io/container/cpu/request_cores
MQL
{ t_0:fetch k8s_container
| metric 'kubernetes.io/container/cpu/core_usage_time'
| ${project_id}
| ${location}
| ${cluster_name}
| ${namespace_name}
| ${top_level_controller_name}
| align rate(1m)
| every 1m
| group_by [pod_name],[value_core_usage_time_aggregate: aggregate(value.core_usage_time)];
t_1:
fetch k8s_container
| metric 'kubernetes.io/container/cpu/request_cores'
| ${project_id}
| ${location}
| ${cluster_name}
| ${namespace_name}
| ${top_level_controller_name}
| group_by 1m, [value_request_cores_mean: mean(value.request_cores)]
| every 1m
| group_by [pod_name],[value_request_cores_mean_aggregate: aggregate(value_request_cores_mean)]
}
| join
| window 5m
| value
[v_0:
cast_units(
div(t_0.value_core_usage_time_aggregate,
t_1.value_request_cores_mean_aggregate) * 100,
"%")]
| group_by [], [.mean()]
kubernetes.io/container/cpu/core_usage_time 並使用給定的變量(project_id、location、cluster_name、namespace_name、top_level_controller_name)進行篩選和分組。value.core_usage_time 的總和。最後使用 rate(1m)函數計算 1 分鐘的速率,並使用 every 1m 函數按每 1 分鐘分組。kubernetes.io/container/cpu/request_cores 從 k8s_container 獲取指定的容器指標數據。該步驟也使用給定的變量(project_id、location、cluster_name、namespace_name、top_level_controller_name)進行篩選和分組。pod_name 進行 mean 函數,計算 value.request_cores 的平均值。最後使用 every 1m 函數按每 1 分鐘分組。 然後,使用 join 操作將 t_0 和 t_1 的結果進行合併,過濾窗口為 5 分鐘。value_core_usage_time_aggregate除以 t_1 的 value_request_cores_mean_aggregate 並乘以 100,以獲取 CPU 核心使用率的百分比。然後使用 group_by 函數對所有結果進行分組,計算平均值。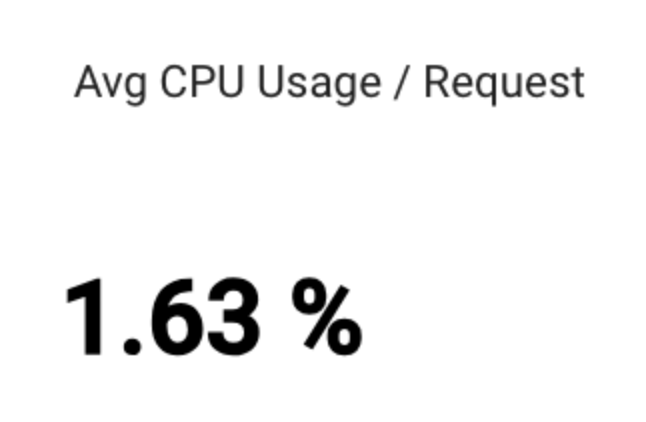
今天舉了一個例子,來思考如何透過資源使用率來觀察系統的效率與性能,明天第二章見!

